Short Answer: K-Nearest Neighbors (KNN) is a supervised machine learning algorithm.
In this comprehensive guide, you’ll learn what makes KNN supervised, how it works step-by-step, and why it’s sometimes mistaken for an unsupervised method. Perfect for beginners and experts alike!
What Is K-Nearest Neighbors (KNN)?
K-Nearest Neighbors (KNN) is a distance-based algorithm used for:
- Classification (e.g., determining if an email is spam or not).
- Regression (e.g., predicting the price of a house).
Instead of building an explicit model with equations, KNN stores the entire training dataset. When new, unseen data appears, KNN makes predictions based on the labeled examples nearest to that new data point.
Key Terms & Concepts
- Distance Metric: Commonly Euclidean distance, but can also be Manhattan distance or others.
- K Value: The number of neighbors KNN considers when classifying or predicting.
Why KNN Is Considered a Supervised Algorithm
- Dependency on Labeled Data
Supervised learning requires examples that are already labeled (known outcomes). KNN uses those labeled data points to classify or predict the label for new data. - Learning by Example
Even though KNN doesn’t build a complicated internal model, it relies on examples with known labels to guide its predictions. This aligns with the definition of supervised learning. - Majority Vote or Averaging
- For classification: KNN looks at the labels of the nearest neighbors and uses a majority vote to decide the new label.
- For regression: It takes the average (or median) of the neighbors’ values to predict a continuous output.
How KNN Works (Step-by-Step)
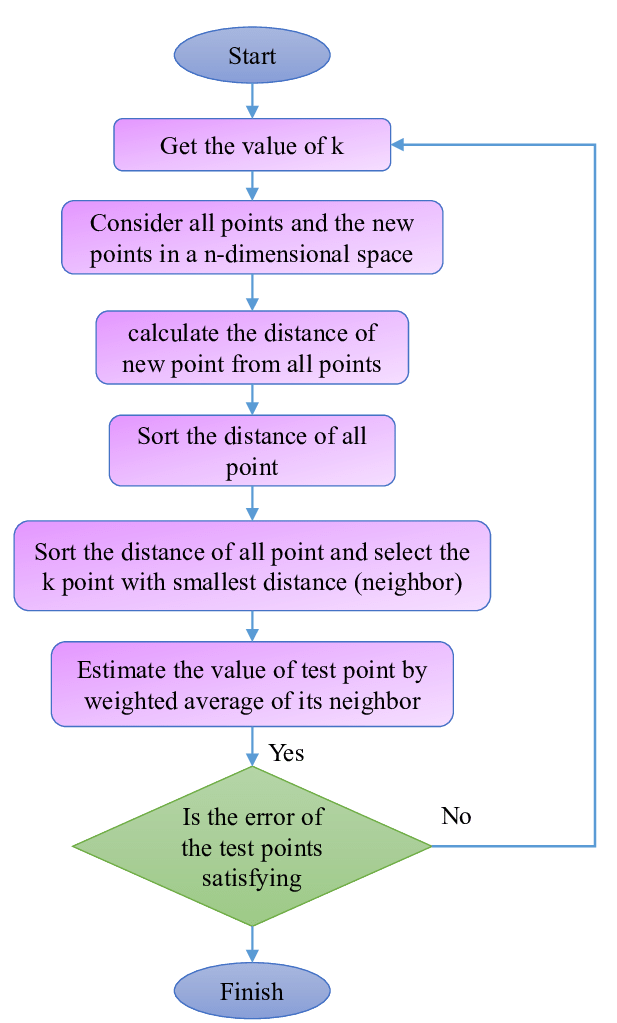
- Training Phase: Store the Data
- There’s no explicit model. KNN just keeps a record (memory) of the entire training set, which includes data points and their labels (e.g., “spam,” “not spam”).
- Calculate Distances
- When a new data point appears, KNN computes a distance measure (e.g., Euclidean distance) between this new data point and all stored points.
- Find the K Nearest Neighbors
- Sort or select the top K points with the smallest distance to the new data point.
- Make a Prediction
- Classification: The algorithm checks the labels of the K nearest neighbors and uses a majority vote to decide the class.
- Regression: The algorithm calculates the average (or weighted average) of the K nearest labels to predict the value.
Common Misconceptions: KNN vs. Unsupervised Learning
1. Storage of the Dataset
- KNN: Stores data with labels.
- Unsupervised Methods (e.g., K-means): They look for patterns without pre-assigned labels.
2. Use of Distance
- Both KNN and many unsupervised clustering algorithms rely on “distance” (Euclidean, Manhattan, etc.).
- Crucial Difference: In unsupervised learning, there are no labels guiding the algorithm’s grouping or clustering.
3. Model vs. Memorization
- KNN is often called a “lazy learner” because it doesn’t build a global model; it just memorizes the dataset.
- Despite this, the presence and usage of labels still classify it under supervised learning.
Key Takeaways
- KNN is definitely supervised because it uses labeled data to predict the label (or value) of new, unseen points.
- It’s often confused with unsupervised algorithms due to its distance-based mechanism and lack of an explicit global model.
- KNN’s simplicity makes it a strong baseline method for many classification and regression problems, though it can be inefficient with very large datasets.
FAQs
1. Can KNN be used for both classification and regression?
Yes! KNN can predict both discrete labels (e.g., “cat” vs. “dog”) and continuous values (e.g., temperature prediction).
2. What is the best distance metric for KNN?
Euclidean distance is common, but the “best” metric depends on your data:
- Euclidean distance works well when features are numeric and on the same scale.
- Manhattan distance can be used for high-dimensional data or data with outliers.
- Minkowski distance generalizes both Euclidean and Manhattan distances.
3. How do I choose the value of K?
- Often chosen through cross-validation.
- A small K might lead to overfitting, while a large K might oversimplify the classification boundaries.
4. Why might KNN be computationally expensive?
For each new data point, KNN calculates a distance to every stored point. This can be slow for very large datasets.
5. Is there a way to speed up KNN?
Yes. Techniques such as k-d trees, ball trees, or using approximate nearest neighbor searches can help reduce computation time.
Final Thoughts!
K-Nearest Neighbors (KNN) firmly belongs to the supervised learning category due to its reliance on labeled data. Whether you’re classifying emails as spam or predicting a house’s price, KNN uses the information from its nearest neighbors to arrive at a final decision. Its straightforward, example-driven approach makes it a favorite for quick baselines and easy-to-understand models in data science and machine learning.
Pro Tip:
To compare KNN with other supervised learning methods, explore Decision Trees vs. KNN or Naive Bayes vs. KNN. Understanding the differences can help you choose the algorithm for your specific use case.

Anuj is an Application Developer at ExxonMobil, Bengaluru, specializing in building and enhancing applications, APIs, and data pipelines. Skilled in C#, Python, and SQL, he supports process automation and technical solutions for the Global Procurement function.